
2026 wird Bot-Traffic für viele Websites und Shops zu einem echten Performance-Problem. Neben Google und Bing greifen heute auch KI-Crawler, SEO-Tools, Social-Media-Bots, Preisvergleichsdienste, Feed-Systeme, Scraper und Wettbewerbs-Monitoring-Tools auf Websites zu.
Das Problem ist nicht Crawling an sich! Crawling ist wichtig für Sichtbarkeit. Kritisch wird es, wenn Bots massenhaft Filterseiten, Suchergebnisse, Sortierungen, Pagination und Parameter-URLs abrufen.
Besonders betroffen sind WooCommerce-, Shopify-, Magento-, Shopware- und andere E-Commerce-Systeme, weil sie durch Produktfilter, Varianten, Collections, Tags und Suchseiten sehr viele URL-Kombinationen erzeugen können.
Die Lösung ist kein pauschales Blockieren aller Bots, sondern intelligentes Crawl-Management:
- wichtige Produktseiten, Kategorien, Collections, Landingpages und Blogartikel offenhalten
- interne Suche, Filterkombinationen, Sortierparameter und tiefe Pagination begrenzen
- seriöse Suchmaschinen und relevante KI-Systeme gezielt zulassen
- Fake-Bots, Scraper und aggressive Crawler erkennen und ausbremsen
- Serverlogs regelmäßig auswerten
- robots.txt, Canonicals, Sitemaps, Caching und Bot-Limiter gemeinsam einsetzen
Ein moderner Bot-Limiter schützt nicht nur den Server, sondern auch SEO, Sichtbarkeit, Ladezeiten, Checkout-Stabilität und Hosting-Kosten.
Übrigens bieten wir hier auch eine SOFORTHILFE an! Einfach schreiben!
Kurz gesagt: Nicht jeder Bot ist schlecht. Aber nicht jeder Bot sollte jede URL unbegrenzt crawlen dürfen.
Crawler-Flut 2026: Warum moderne Websites einen intelligenten Bot-Limiter brauchen um echt von unecht sowie sinnvoll und nicht sinnvoll zu unterscheiden.
Früher war Crawling vergleichsweise überschaubar. Eine Website wurde vor allem von Google, Bing und wenigen weiteren Suchmaschinen regelmäßig besucht. Das war technisch kalkulierbar und aus SEO-Sicht sogar ausdrücklich erwünscht.
2026 sieht die Realität anders aus.

Wie Suchmaschinen, KI-Bots, SEO-Tools und Scraper moderne Websites überlasten – und warum pauschales Blockieren keine Lösung ist
Heute greifen nicht mehr nur klassische Suchmaschinen auf Websites zu. Hinzu kommen KI-Crawler, KI-Suchsysteme, SEO-Tools, Social-Media-Bots, Link-Preview-Crawler, Feed-Systeme, Preisvergleichsdienste, Monitoring-Tools, Commerce-Plattformen, Scraper, Wettbewerbsanalysen und Datenanbieter, die eigene Indizes aufbauen wollen.
Jeder dieser Systeme verfolgt ein legitimes oder zumindest nachvollziehbares Ziel: Inhalte erfassen, Produkte verstehen, Preise vergleichen, Snippets erzeugen, Daten trainieren, Suchergebnisse verbessern oder neue Antwortsysteme mit Informationen versorgen. Das Problem entsteht dort, wo aus nützlichem Crawling unkontrollierte technische Last wird.
Sichtbar/er werden bei Google & Social Media?
In einem kostenlosen Strategiegespräch für datenbasiertes Online-Marketing, decken wir Ihre ungenutzten Potenziale auf, überprüfen ggf. vorhandene Anzeigenkonten, schauen uns das SEO-Ranking und die Sichtbarkeit an und prüfen was zu Ihrem Budget die passende Strategie ist und welche aktiven Maßnahmen zu mehr Anfragen oder Verkäufen führen.

✅ Mehr Sichtbarkeit & Wahrnehmung durch gezielte Platzierung
✅ Mehr Besucher > Interessenten > Kunden > Umsatz
✅ Mit SEA skalierbar Zielgruppe ansprechen
✅ Mit SEO nachhaltig agieren und wachsen
🫵 Maximale Erfolge mit unserer Hybrid-Strategie
💪 Mehr als 15 Jahre Erfahrung branchenübergreifend in über 1.000+ Projekten nachweisbar!




Unser Video dazu:
Wichtige Begriffe und Benennungen:
Fraud = Betrug / missbräuchliche Handlung
Fraud bezeichnet absichtliche Täuschung oder Manipulation mit wirtschaftlichem Schaden. Im Web-Kontext meint das z. B. Klickbetrug, Fake-Leads, gefälschte Bestellungen, Account-Missbrauch oder automatisierte Aktionen mit betrügerischer Absicht.
Bot = automatisiertes Programm
Ein Bot ist ein Softwareprogramm, das Aufgaben automatisch ausführt. Bots können nützlich sein, z. B. Suchmaschinen-Bots, Monitoring-Bots oder Sicherheits-Scanner, aber auch schädlich, z. B. Spam-Bots, Scraper oder Angriffsbots.
Crawler = Bot zum Durchsuchen von Webseiten
Ein Crawler ruft Webseiten systematisch auf, folgt Links und sammelt Inhalte. Seriöse Crawler wie Googlebot oder Bingbot dienen der Indexierung. Problematisch werden Crawler, wenn sie zu viele Seiten zu schnell abrufen oder Shops durch Filter-, Such- und Parameter-URLs überlasten.
Scraper = Bot zum Kopieren von Inhalten oder Daten
Ein Scraper liest Webseiten aus, um Inhalte, Preise, Produktdaten, Bilder oder Texte automatisiert zu kopieren. Im E-Commerce können Scraper Serverlast erzeugen, Wettbewerbsdaten abgreifen oder Content-Diebstahl verursachen.
Good Bot = erwünschter Bot
Ein Good Bot erfüllt einen legitimen Zweck, z. B. Googlebot, Bingbot, Zahlungsanbieter-Prüfungen, Monitoring-Dienste oder SEO-Tools, wenn sie kontrolliert und regelkonform arbeiten.
Bad Bot = unerwünschter oder schädlicher Bot
Ein Bad Bot verursacht Spam, Scraping, Fake-Traffic, Credential-Stuffing, Formularmissbrauch, Warenkorb-Manipulation oder massive Serverlast. Nicht jeder Bad Bot ist sofort ein Hackerangriff, aber er kann wirtschaftlich und technisch erheblichen Schaden verursachen.
AI Crawler = Crawler für KI-Systeme
AI Crawler sammeln Webseiteninhalte, um KI-Suchsysteme, Sprachmodelle oder Antwortmaschinen mit Informationen zu versorgen. Für Unternehmen kann das Sichtbarkeit bringen, gleichzeitig aber Serverlast und Kontrollverlust über Inhalte erzeugen.
Rate Limiting = Begrenzung von Zugriffen
Rate Limiting beschränkt, wie viele Anfragen ein Nutzer, Bot oder eine IP-Adresse innerhalb eines bestimmten Zeitraums stellen darf. Ziel ist es, normale Besucher nicht zu behindern, aber übermäßige Zugriffe zu bremsen.
Bot Limiter = intelligentes System zur Bot-Steuerung
Ein Bot Limiter erkennt verdächtige Zugriffsmuster und begrenzt, verzögert oder blockiert problematische Anfragen. Im Idealfall unterscheidet er zwischen echten Besuchern, guten Suchmaschinen-Bots und schädlichen Bots.
Burst = Stoß / Schwall.
Im Network-/Bot-Detection-Kontext: eine Phase in der sehr viele Requests in sehr kurzer Zeit von einer IP kommen.
DDoS = massiver Überlastungsangriff
DDoS steht für „Distributed Denial of Service“. Dabei wird eine Website oder ein Server durch sehr viele gleichzeitige Anfragen überlastet. Im Unterschied zur normalen Crawler-Flut ist ein DDoS meist gezielt destruktiv angelegt.
Serverlast = technische Belastung des Servers
Serverlast entsteht durch Datenbankabfragen, PHP-Prozesse, Warenkorb-Requests, Filterseiten, Suchanfragen, Bildaufrufe oder viele parallele Besucher/Bots. Hohe Serverlast führt zu langsamen Ladezeiten, Fehlern oder Ausfällen.
Lastspitze = kurzfristig stark erhöhte Auslastung
Eine Lastspitze ist ein plötzlicher Anstieg von Zugriffen oder Serverprozessen. Sie kann durch echte Besucher, Kampagnen, Bots, Crawler, Angriffe oder falsch konfigurierte Tools entstehen.
Was bedeutet das also für Besucher, Server, Ladezeit und Sicherheit von Webseite und Shop?
Für einfache Unternehmenswebsites ist das oft kaum spürbar. Für große Shops (egal welches System!), WooCommerce-Systeme, Verzeichnisse, Portale und Websites mit vielen Filtern, Parametern, Pagination, Sortierungen und interner Suche kann Crawling jedoch zu einem echten Performance- und Kostenproblem werden.
Eine Serverauslastung kann dann schnell um das 10-fache oder mehr steigen wie hier zu sehen:
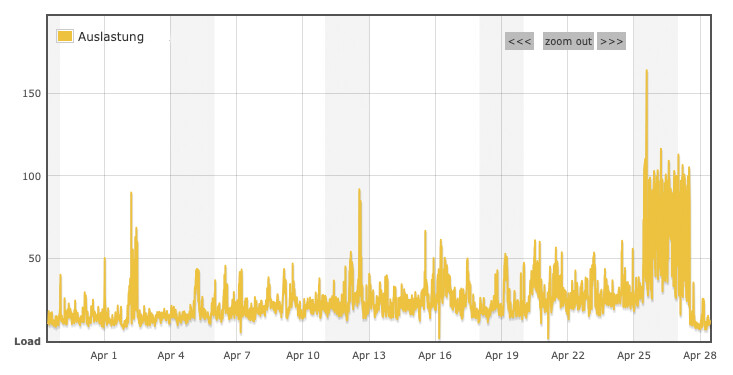
Wochenansicht: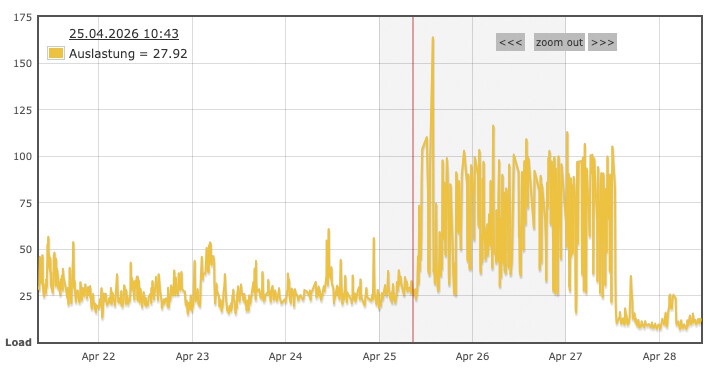
Google selbst weist darauf hin, dass facettierte Navigationen und gefilterte URLs enorme Mengen an URL-Kombinationen erzeugen können und häufig unnötig Serverressourcen verbrauchen, wenn Crawler diese ungefiltert abrufen. Für viele gefilterte Produktlisten empfiehlt Google deshalb, Crawling gezielt über robots.txt zu steuern, wenn diese URLs keinen eigenständigen Suchwert haben.
Genau hier setzt die zentrale Frage an:
Wie bleibt eine Website für Suchmaschinen und relevante KI-Systeme sichtbar, ohne dass Bots Server, Datenbank und Shop-Funktionen überlasten?
Die Antwort ist nicht: „Alle Bots blockieren.“
Die Antwort ist: intelligentes Crawl-Management.
Empfehlung für ein sehr sehr gutes und preiswertes Hosting ist immer All-Inkl ab dem BUSINESS-Paket*!
Was ist mit „Crawler-Flut“ gemeint?
Mit Crawler-Flut ist nicht gemeint, dass jeder Bot automatisch schädlich ist. Crawling ist ein Grundbestandteil des offenen Webs. Ohne Crawler gäbe es keine Google-Suche, keine Bing-Suche, keine Produktanzeigen, keine Link-Vorschauen, keine SEO-Analysen und keine Sichtbarkeit in vielen modernen Antwortsystemen.
Das Problem ist die Menge, Geschwindigkeit und Tiefe der Zugriffe.
Ein einzelner Bot, der gelegentlich wichtige Seiten besucht, ist unkritisch. Problematisch wird es, wenn viele Systeme gleichzeitig komplette Shops, Filterseiten, Suchergebnisse, Parameterkombinationen und Paginationsseiten abrufen.

Typische Bot-Gruppen sind:
- klassische Suchmaschinen-Crawler wie Googlebot oder Bingbot
- Bild-, News-, Video- und Commerce-Crawler
- KI-Crawler und KI-Suchsysteme
- SEO-Tools zur Index-, Backlink- und Ranking-Analyse
- Social-Media- und Messenger-Bots für Link-Vorschauen
- Preisvergleichs- und Shopping-Systeme
- Feed- und Marktplatz-Crawler
- Scraper und automatisierte Wettbewerbsbeobachtung
- nicht identifizierbare Bots mit wechselnden User-Agents oder IPs
Google dokumentiert selbst unterschiedliche Crawler für verschiedene Suchprodukte und Anwendungsfälle, darunter Googlebot, Googlebot-Image, Googlebot-Video und weitere spezialisierte Systeme. Crawling ist also längst nicht mehr nur ein einzelner Bot mit einem einfachen Zugriffsmuster.
OpenAI beschreibt ebenfalls mehrere Crawler beziehungsweise User-Agents für unterschiedliche Zwecke, unter anderem für Websuche, Training und nutzerinitiierte Abrufe. Website-Betreiber können diese Zugriffe über robots.txt differenziert steuern. (developers.openai.com)
Common Crawl betreibt mit CCBot einen eigenen Webcrawler und stellt ebenfalls eine Möglichkeit bereit, den Zugriff über robots.txt zu unterbinden. (commoncrawl.org)
Das zeigt: Crawling ist 2026 kein einheitlicher Vorgang mehr. Es ist ein Ökosystem aus vielen Akteuren mit unterschiedlichen Interessen.
Empfehlung:

Warum besonders WooCommerce-Shops betroffen sind
WooCommerce-Shops sind besonders anfällig, weil sie häufig sehr viele technische URL-Varianten erzeugen.
Ein Shop mit 1.000 Produkten kann durch Filter, Kategorien, Marken, Farben, Größen, Materialien, Sortierungen und Pagination schnell zehntausende oder hunderttausende abrufbare URLs erzeugen.
Beispiele:
/shop/?filter_farbe=blau
/shop/?filter_farbe=blau&filter_material=baumwolle
/shop/?filter_marke-hersteller=...
/shop/page/48/?filter_farbe=blau&orderby=price
/shop/?per_page=96
/?s=suchbegriff&post_type=product
/verwendung/sessel/page/259/?filter_...
Für Nutzer sind manche dieser URLs sinnvoll. Wer blaue Baumwollprodukte sucht, möchte filtern können. Für Suchmaschinen sind aber längst nicht alle Kombinationen wertvoll. Viele Filterseiten haben keinen eigenständigen Suchintent, keine individuellen Inhalte, keine Backlinks und keine Relevanz als Landingpage.
Technisch können sie trotzdem teuer sein.
Denn jede dieser Seiten kann Datenbankabfragen auslösen:
- Produktabfragen
- Taxonomie-Abfragen
- Meta-Queries
- Preisfilter
- Attributfilter
- Sortierungen
- Pagination
- Bestandsermittlung
- Variantenlogik
- Theme-Templates
- WooCommerce-Hooks
- Drittanbieter-Plugins
- Caching-Bypässe durch Query-Parameter
Gerade WooCommerce-Systeme mit vielen Attributen und Filtern erzeugen oft komplexe SQL-Abfragen. Wenn Bots massenhaft solche URLs abrufen, entsteht Last nicht primär durch die Startseite oder Produktseiten, sondern durch technisch teure Listen-, Such- und Filterseiten.
Das Ergebnis:
- hohe CPU-Last
- hoher RAM-Verbrauch
- langsame Datenbankabfragen
- überfüllte PHP-FPM-Worker
- Timeouts
- 500er-Fehler
- schlechtere Core Web Vitals
- instabiler Checkout
- langsamer Adminbereich
- steigende Hosting- oder Serverkosten
Im schlimmsten Fall konkurrieren Bots mit echten Kunden um Serverressourcen.

Das Kernproblem: Crawler verstehen nicht automatisch, was wirtschaftlich wichtig ist
Ein Bot sieht zunächst nur URLs.
Er weiß nicht automatisch, dass /produkt/mein-bestseller/ für den Shop wertvoll ist, während /shop/page/259/?filter_farbe=blau&orderby=price-desc&per_page=96 wahrscheinlich keinen eigenständigen SEO-Wert hat.
Er weiß auch nicht, dass eine bestimmte interne Suchseite 20 Datenbankabfragen auslöst oder dass ein bestimmter Filter technisch teuer ist.
Aus Sicht des Bots gilt oft: Wenn eine URL erreichbar ist, kann sie gecrawlt werden.
Aus Sicht des Website-Betreibers gilt aber: Nicht jede erreichbare URL sollte unbegrenzt gecrawlt werden.
Genau darin liegt der Unterschied zwischen technischer Erreichbarkeit und strategischer Crawl-Freigabe.
Warum pauschales Blockieren gefährlich ist
Viele Website-Betreiber reagieren auf Bot-Last zunächst reflexartig:
„Dann blockieren wir einfach alle Bots.“
Das klingt logisch, ist aber gefährlich.
Denn Crawling ist die Grundlage für Sichtbarkeit. Wer zu viel blockiert, riskiert:
- schlechtere Indexierung
- verzögerte Aktualisierung von Produktseiten
- schlechtere Sichtbarkeit in Google und Bing
- weniger Auffindbarkeit in KI-Suchsystemen
- Probleme mit Link-Vorschauen in Social Media
- fehlerhafte Produktdaten in Commerce-Systemen
- weniger Daten für SEO-Tools und Monitoring
Google weist im Zusammenhang mit Crawl-Budget ausdrücklich darauf hin, dass robots.txt Crawling verhindert und dadurch die Wahrscheinlichkeit deutlich sinkt, dass blockierte URLs von Google-Systemen verarbeitet oder indexiert werden. Gleichzeitig ist noindex für Crawl-Budget-Probleme oft keine effiziente Lösung, weil die Seite trotzdem erst abgerufen werden muss, bevor Google das noindex sehen kann.
Das bedeutet:
Wer falsch blockiert, spart vielleicht Serverlast, verliert aber Sichtbarkeit.
Ein guter Bot-Limiter darf deshalb nicht grob sein. Er muss unterscheiden können.

Die richtige Strategie: nicht blockieren, sondern steuern
Ein moderner Bot-Limiter verfolgt nicht das Ziel, alle Crawler auszusperren.
Er verfolgt drei Ziele:
- Wichtige Bots dürfen wichtige Inhalte zuverlässig crawlen.
- Unwichtige oder teure URL-Muster werden begrenzt.
- Aggressive, unnötige oder schädliche Zugriffe werden reduziert oder blockiert.
Das ist ein fundamentaler Unterschied.
Ein schlechter Bot-Schutz denkt in Schwarz-Weiß:
Bot = schlecht
Mensch = gut
Ein intelligenter Bot-Limiter denkt in Kategorien:
Googlebot auf Produktseiten = wichtig
Googlebot auf endlosen Filterkombinationen = begrenzen
KI-Suchbot auf redaktionellen Inhalten = strategisch relevant
SEO-Tool mit moderater Frequenz = nützlich
Scraper mit hoher Frequenz = blockieren
Unbekannter Bot auf Suchseiten = stark limitieren
Das Ziel ist nicht maximale Abschottung.
Das Ziel ist SEO-sichere Priorisierung.
Was ein intelligenter Bot-Limiter können muss
Ein intelligenter Bot-Limiter sollte nicht nur User-Agents lesen und pauschal blockieren. Das wäre zu einfach und zu unsicher.
Er sollte mehrere Signale kombinieren:
- User-Agent
- IP-Adresse
- Reverse-DNS-Prüfung bei wichtigen Suchmaschinen
- URL-Muster
- Query-Parameter
- Anfragefrequenz
- Zugriffstiefe
- HTTP-Methode
- Referrer
- bekannte Bot-Kategorien
- Verhalten über Zeit
- Serverlast
- Seitenwert aus SEO-Sicht
Besonders wichtig ist die Unterscheidung zwischen Bot-Typ und URL-Typ.
Denn ein guter Bot auf einer schlechten URL kann trotzdem problematisch sein.
Beispiel:
Googlebot auf wichtigen Produktseiten:
/produkt/ergonomischer-buerostuhl/
→ erwünscht.
Googlebot auf endlosen Filter- und Pagination-Kombinationen:
/shop/page/259/?filter_farbe=blau&orderby=price&per_page=96
→ häufig nicht sinnvoll.
Unbekannter Bot auf interner Suche:
/?s=xyz&post_type=product
→ meist begrenzen oder blockieren.
Scraper auf Preis- und Produktseiten mit hoher Frequenz:
/produkt/...
→ abhängig vom Geschäftsmodell stark limitieren oder blockieren.
Die gefährlichsten URL-Muster für Shops
Aus Performance- und SEO-Sicht sind vor allem diese URL-Typen kritisch:
1. Filter-URLs
/shop/?filter_farbe=blau
/shop/?filter_farbe=blau&filter_groesse=xl
/shop/?filter_material=leder&filter_marke=...
Filter erzeugen schnell Millionen möglicher Kombinationen. Manche sind wertvoll, viele nicht.
2. Sortierparameter
/shop/?orderby=price
/shop/?orderby=popularity
/shop/?orderby=rating
Sortierungen verändern meist nur die Reihenfolge, nicht den eigentlichen Inhalt. Für Suchmaschinen entsteht dadurch oft kein neuer Mehrwert.
3. Pagination mit Filtern
/shop/page/48/?filter_farbe=blau
/verwendung/sessel/page/259/?filter_...
Tiefe Pagination ist für Bots besonders gefährlich, weil sie große URL-Räume öffnet.
4. Interne Suche
/?s=suchbegriff
/?s=suchbegriff&post_type=product
Interne Suchseiten können durch Bots massenhaft generiert werden. Oft enthalten sie dünne, doppelte oder irrelevante Inhalte.
5. Per-Page-Parameter
/shop/?per_page=96
/shop/?per_page=120
Diese URLs können besonders teuer werden, weil mehr Produkte pro Request geladen werden.
6. Kombinierte Parameter
/shop/page/20/?filter_farbe=blau&filter_material=baumwolle&orderby=price&per_page=96
Hier entsteht die eigentliche Last. Nicht ein einzelner Parameter ist das Problem, sondern die kombinatorische Explosion.
Google beschreibt genau dieses Problem bei facettierter Navigation: Parameterkombinationen können enorme Mengen an URLs erzeugen, die häufig nur geringen oder keinen eigenständigen Nutzen haben, aber Crawling-Ressourcen und Serverleistung verbrauchen.
SEO-sicheres Crawl-Management: Was sollte erlaubt bleiben?
Ein Bot-Limiter darf nicht versehentlich die wichtigsten Seiten abschneiden.
In der Regel sollten folgende Bereiche für seriöse Suchmaschinen gut erreichbar bleiben:
- Startseite
- Hauptkategorien
- strategische SEO-Kategorieseiten
- Produktseiten
- wichtige Ratgeberseiten
- Blogartikel
- Landingpages
- Marken- oder Herstellerseiten mit echtem Suchintent
- statische Informationsseiten
- strukturierte Daten
- XML-Sitemaps
- wichtige Bilder, wenn Bildersuche relevant ist
Google weist darauf hin, dass verschiedene Google-Crawler für unterschiedliche Suchprodukte und Funktionen zuständig sind. Deshalb sollte man nicht blind alle Googlebot-Varianten gleich behandeln, sondern verstehen, welche Bereiche für welche Sichtbarkeit relevant sind.
Für WooCommerce bedeutet das:
Produktseiten und wichtige Kategorien sind Crawl-Priorität. Filterkombinationen, interne Suche und tiefe Parameter-URLs sind Crawl-Risiko.
robots.txt ist wichtig – aber nicht genug
Die robots.txt ist ein zentrales Werkzeug für Crawl-Steuerung. Sie kann Crawlern mitteilen, welche Bereiche nicht gecrawlt werden sollen.
Beispiel:
User-agent: *
Disallow: /*?s=
Disallow: /*?filter_
Disallow: /*orderby=
Disallow: /*per_page=
Das kann sinnvoll sein, muss aber sauber geplant werden.
Warum?
Weil robots.txt nur freiwillig respektiert wird. Seriöse Bots halten sich daran. Aggressive Scraper nicht unbedingt.
Außerdem kann robots.txt zu grob sein. Vielleicht möchte man bestimmte Filterseiten blockieren, aber einzelne SEO-Landingpages mit sauberer URL-Struktur erlauben. Vielleicht sollen Google und Bing bestimmte Bereiche crawlen, während SEO-Tools oder KI-Trainingscrawler stärker begrenzt werden.
Google beschreibt in seiner robots.txt-Dokumentation außerdem, dass bei mehreren Gruppen die spezifischste passende User-Agent-Gruppe zählt. Falsch strukturierte Regeln können deshalb anders wirken als erwartet. (Google for Developers)
Die robots.txt ist also wichtig, aber sie ist kein vollständiger Bot-Limiter.
Sie ist eine Crawl-Anweisung.
Ein intelligenter Bot-Limiter ist eine technische Durchsetzungsebene.

Warum klassische Rate Limits oft nicht ausreichen
Viele Server-Setups arbeiten mit einfachen Rate Limits:
Maximal 100 Requests pro Minute pro IP
Das kann helfen, ist aber bei moderner Bot-Last oft zu ungenau.
Problem 1: Seriöse Crawler können mit vielen IPs arbeiten.
Problem 2: Ein einzelner teurer Request kann mehr Last verursachen als zehn einfache Requests.
Problem 3: Ein Limit pro IP erkennt nicht, ob eine URL SEO-wichtig oder technisch wertlos ist.
Problem 4: Gute Bots sollen nicht unnötig ausgebremst werden, wenn sie wichtige Seiten crawlen.
Problem 5: Schlechte Bots tarnen sich teilweise als Browser oder bekannte Crawler.
Ein intelligenter Bot-Limiter sollte deshalb nicht nur zählen, sondern bewerten.
Nicht nur:
Wie viele Requests?
Sondern:
Wer fragt an?
Was wird angefragt?
Wie oft?
Mit welchem Muster?
Wie teuer ist diese URL?
Wie wichtig ist diese URL?
Ein gutes Regelmodell für WooCommerce-Shops und andere Shopsysteme
Ein praxistauglicher Bot-Limiter für WooCommerce kann mit mehreren Prioritätsstufen arbeiten.
Stufe 1: Immer erlauben
Für vertrauenswürdige Bots und wichtige URLs:
/
/produkt/
/produkt-kategorie/
/marke/
/blog/
/ratgeber/
/sitemap.xml
Aber nur, wenn die Anfragen moderat bleiben und die Bot-Identität plausibel ist.
Stufe 2: Erlauben, aber begrenzen
Für Bots auf mittelwichtigen Bereichen:
/page/2/
/produkt-kategorie/.../page/3/
/tag/
/author/
Hier kann ein sanftes Rate Limit sinnvoll sein.
Stufe 3: Stark begrenzen
Für teure oder meist unwichtige Muster:
?filter_
?orderby=
?per_page=
?s=
/page/50/
Diese URLs sollten nicht unbegrenzt gecrawlt werden.
Stufe 4: Blockieren
Für eindeutig problematische Muster:
?s=beliebige-bot-suche
?add-to-cart=
?wc-ajax=
/cart/
/checkout/
/my-account/
Checkout, Warenkorb, Account-Bereiche und AJAX-Endpunkte sollten für Bots grundsätzlich nicht als Crawling-Ziel dienen.
Stufe 5: Eskalieren
Für aggressive Scraper:
- hohe Frequenz
- wechselnde Parameter
- fehlende Asset-Requests
- ungewöhnliche User-Agents
- keine Cookie- oder Session-Logik
- wiederholte Zugriffe auf teure URLs
- Abruf vieler Produktseiten in kurzer Zeit
Hier sind harte Limits, temporäre Sperren oder Challenge-Mechanismen sinnvoll.
Besonders wichtig: Googlebot nicht blind vertrauen
Viele Bots geben sich als Googlebot aus. Deshalb reicht der User-Agent allein nicht aus.
Ein Zugriff mit:
Mozilla/5.0 ... Googlebot/2.1
ist nicht automatisch echter Googlebot.
Für wichtige Suchmaschinen sollte idealerweise eine Verifizierung über IP und Reverse-DNS erfolgen. Google dokumentiert, dass Website-Betreiber Google-Crawler verifizieren können, statt sich ausschließlich auf den User-Agent zu verlassen.
Das ist besonders wichtig, wenn Regeln zwischen echten Suchmaschinen und Fake-Bots unterscheiden sollen.
Empfehlung:

KI-Crawler: blockieren, erlauben oder begrenzen?
KI-Crawler sind 2026 ein strategisches Thema.
Einerseits möchten viele Unternehmen in KI-Suchsystemen und Antwortmaschinen sichtbar werden. Andererseits wollen sie nicht, dass komplette Inhalte, Produktdaten oder Preisstrukturen unkontrolliert abgegriffen werden.
Die Entscheidung ist deshalb nicht rein technisch. Sie ist strategisch.
Mögliche Ansätze:
1. KI-Suchbots erlauben
Sinnvoll, wenn Sichtbarkeit in KI-Antwortsystemen wichtig ist.
2. KI-Training-Bots begrenzen oder blockieren
Sinnvoll, wenn Inhalte nicht für Trainingszwecke verwendet werden sollen.
3. Redaktionelle Inhalte erlauben, Shop-Parameter begrenzen
Oft der beste Mittelweg.
4. Produktseiten selektiv erlauben
Sinnvoll, wenn KI-Systeme Produkte finden dürfen, aber keine teuren Filter- und Suchseiten crawlen sollen.
OpenAI unterscheidet eigene Crawler beziehungsweise User-Agents nach Anwendungsfällen und ermöglicht Website-Betreibern eine getrennte Steuerung über robots.txt.
Das ist wichtig: KI-Crawler sind nicht automatisch gleich. Ein Bot für nutzerinitiierte Suche ist anders zu bewerten als ein Bot für Trainingsdaten oder ein generischer Datencrawler.

Der Unterschied zwischen Crawl-Management und Bot-Abwehr
Viele Sicherheitslösungen betrachten Bots primär als Bedrohung. Das ist bei DDoS, Credential-Stuffing oder Spam auch richtig.
Bei SEO und Shops ist die Lage komplexer.
Ein Googlebot ist kein Angreifer. Ein Social-Media-Link-Preview-Bot ist kein Angreifer. Ein SEO-Tool ist nicht automatisch schädlich. Ein KI-Suchcrawler kann strategisch wertvoll sein.
Aber alle können Last erzeugen.
Deshalb braucht es eine eigene Kategorie:
Crawl-Management.
Crawl-Management sitzt zwischen SEO, Serveradministration, Performance-Optimierung und Security.
Es geht nicht nur um Schutz.
Es geht um Steuerung.
Warum Caching allein das Problem nicht löst
Viele Shop-Betreiber denken zuerst an Caching. Das ist verständlich.
Ein guter Cache reduziert Last massiv. Aber Bot-Traffic auf WooCommerce-Parameterseiten ist oft schwer cachebar.
Gründe:
- Query-Parameter erzeugen viele Cache-Varianten
- Warenkorb- und Session-Cookies umgehen den Cache
- Filterseiten erzeugen dynamische Inhalte
- Sortierungen erzeugen neue HTML-Versionen
- Plugins setzen no-cache Header
- personalisierte Preise oder Steuerlogik verhindern statisches Caching
- Bots rufen URLs ab, die noch nie gecacht wurden
Ein Cache hilft bei häufig angefragten Seiten. Er hilft weniger bei einer Bot-Flut aus immer neuen URL-Kombinationen.
Deshalb gilt:
Caching reduziert die Kosten pro Request. Ein Bot-Limiter reduziert unnötige Requests selbst.
Beides gehört zusammen.

Praxisbeispiel: Der Shop ist nicht wegen Kunden langsam, sondern wegen Bots
Ein typisches Szenario:
Ein WooCommerce-Shop hat 20.000 Produkte, viele Attribute und Filter. Tagsüber steigen CPU und RAM plötzlich stark an. Der Checkout wird langsam. Im Error-Log tauchen Memory-Limit-Fehler auf. Die Datenbank zeigt lange Abfragen. Der Betreiber vermutet zunächst ein Plugin-Problem.
Bei genauer Analyse zeigt sich:
- viele Requests auf
/shop/page/.../ - viele Filterkombinationen
- interne Suchanfragen mit
?s= - Abrufe mit
orderby=price - hohe Frequenz durch Bots
- echte Nutzer machen nur einen kleinen Teil der Last aus
Der Shop hat also nicht primär ein „Traffic-Problem“.
Er hat ein Crawl-Qualitätsproblem.
Die Lösung besteht nicht darin, die Website komplett zu verstecken, sondern den Crawl-Raum zu verkleinern:
- wichtige Produktseiten offenhalten
- Sitemaps sauber pflegen
- Filterkombinationen begrenzen
- tiefe Pagination reduzieren
- interne Suche für Bots sperren
- bekannte gute Bots verifizieren
- aggressive Bots ausbremsen
- Serverlogs regelmäßig auswerten
Was Website-Betreiber jetzt prüfen sollten
Wer wissen will, ob die eigene Website betroffen ist, sollte nicht raten, sondern Logs analysieren.
Wichtige Fragen:
- Welche User-Agents verursachen die meisten Requests?
- Welche URLs werden am häufigsten von Bots abgerufen?
- Wie viele Requests gehen auf Parameter-URLs?
- Wie oft wird die interne Suche gecrawlt?
- Wie tief gehen Bots in Pagination?
- Welche Requests erzeugen 500er, 502er, 503er oder Timeouts?
- Welche Bots ignorieren
robots.txt? - Welche Bots treffen den Checkout, Warenkorb oder AJAX-Endpunkte?
- Welche URLs sind SEO-wichtig und welche nicht?
- Welche Bereiche verursachen hohe Datenbanklast?
Besonders aufschlussreich sind kombinierte Auswertungen:
User-Agent + URL-Muster + Statuscode + Antwortzeit
Denn ein Bot mit vielen schnellen Requests ist weniger problematisch als ein Bot mit weniger, aber extrem teuren Requests.
Tipp: Hosting & Server bei All-Inkl ab dem BUSINESS-Paket buchen*
Konkrete Maßnahmen für WooCommerce
1. Interne Suche für Bots begrenzen
Interne Suchseiten sind selten gute SEO-Landingpages. Sie können unendlich viele dünne Seiten erzeugen.
Typisches Muster:
Disallow: /*?s=
Zusätzlich kann serverseitig ein Limit greifen, wenn Bots Such-URLs abrufen.
2. Filterparameter prüfen
Nicht jeder Filter sollte crawlbar sein.
Beispiel:
Disallow: /*?filter_
Disallow: /*&filter_
Aber Achtung: Wenn bestimmte Filterseiten bewusst als SEO-Landingpages genutzt werden, sollten sie eigene saubere URLs und eigene Inhalte erhalten.
3. Sortierparameter blockieren
Sortierungen ändern meist nur die Reihenfolge.
Disallow: /*orderby=
4. Per-Page-Parameter begrenzen
Disallow: /*per_page=
Gerade hohe Produktanzahlen pro Seite können teuer sein.
5. Tiefe Pagination begrenzen
Nicht jede Seite 259 einer Kategorie ist crawl-wichtig.
Eine mögliche Regelstrategie:
- Seite 1–3 offen
- danach begrenzen
- sehr tiefe Pagination für Bots sperren oder verlangsamen
6. Sitemaps stärken
Bots sollten nicht raten müssen. Gute XML-Sitemaps helfen, relevante Produkt-, Kategorie- und Inhaltsseiten gezielt zu finden.
7. Canonicals sauber setzen
Filter-, Sortier- und Parameterseiten sollten klare Canonical-Strategien haben.
8. Facetten mit SEO-Wert separat behandeln
Wenn „blaue Baumwollstoffe“ ein echtes Suchvolumen und Conversion-Potenzial haben, sollte daraus besser eine echte Landingpage werden statt eine zufällige Parameter-URL.
9. Fake-Bots erkennen
Bekannte Bots sollten nicht nur über User-Agent erkannt werden. Gerade bei Googlebot ist eine Verifizierung wichtig.
10. Serverlast als Signal nutzen
Ein intelligenter Limiter kann dynamischer reagieren:
- niedrige Last: mehr Crawling zulassen
- hohe Last: teure Bot-URLs stärker begrenzen
- kritische Last: aggressive Bots temporär blockieren

Nicht nur WooCommerce: Auch Shopify, Magento, Shopware und andere Shopsysteme sind betroffen
Das Problem betrifft nicht nur WooCommerce. Auch Shopify, Magento, Shopware, PrestaShop, Salesforce Commerce Cloud und andere E-Commerce-Systeme können durch unkontrolliertes Crawling stark belastet werden. Die technische Umsetzung unterscheidet sich je nach Plattform, das Grundproblem bleibt jedoch gleich: Moderne Shops erzeugen durch Kategorien, Produktvarianten, Filter, Sortierungen, interne Suche, Tags, Collections, Pagination und Tracking-Parameter sehr viele abrufbare URL-Varianten.
Bei Shopify können beispielsweise Collections, Tags, Sortierungen, Suchseiten und Parameter-URLs zusätzliche Crawl-Pfade erzeugen. Bei Magento und Shopware entstehen ähnliche Muster durch Layered Navigation, Attributfilter, Preisfilter, Herstellerseiten, Sortierungen und paginierte Kategorieseiten. Besonders kritisch wird es, wenn Bots nicht nur einzelne Produkt- oder Kategorieseiten abrufen, sondern systematisch jede mögliche Kombination aus Farbe, Größe, Marke, Preisbereich, Material, Verfügbarkeit und Sortierung durchlaufen.
Für den Server macht es dabei keinen großen Unterschied, ob die Plattform WooCommerce, Shopify, Magento oder Shopware heißt. Jeder unnötige Bot-Aufruf kann Datenbankabfragen, Template-Rendering, App-Logik, Plugin-Logik, Cache-Varianten oder externe API-Prozesse auslösen.
Deshalb brauchen größere Shopsysteme grundsätzlich eine durchdachte Crawl-Strategie: wichtige Produktseiten, Kategorien und Landingpages sollen sichtbar bleiben, während irrelevante Filter-, Such-, Sortier- und Parameter-URLs begrenzt oder vom Crawling ausgeschlossen werden. Ein intelligenter Bot-Limiter ist damit kein reines WooCommerce-Thema, sondern ein zentrales Performance- und SEO-Thema für moderne E-Commerce-Architekturen.
Konkrete Empfehlung für Shopify-Shops
Bei Shopify sollten Shop-Betreiber besonders auf Collections, Tags, Sortierungen, Suchseiten und Parameter-URLs achten. Shopify ist als Plattform grundsätzlich sehr performant, aber auch hier können Bots unnötige Crawl-Pfade erzeugen, wenn sie systematisch Collections, Tag-URLs, interne Suchergebnisse oder sortierte Varianten abrufen.
Typische Shopify-URLs, die geprüft werden sollten:
/collections/alle-produkte
/collections/sommerkleider
/collections/sommerkleider/blau
/collections/sommerkleider?sort_by=price-ascending
/search?q=produktname
/search?type=product&q=...
/products/produktname?variant=...
Die wichtigste Empfehlung lautet: Produktseiten, Haupt-Collections und strategische SEO-Landingpages offenhalten – aber Suchseiten, irrelevante Tag-Kombinationen, Sortierparameter und unnötige Parameter-URLs begrenzen.
Bei Shopify sollte man besonders prüfen:
- ob Collection-Tags wirklich SEO-relevant sind oder nur interne Filterlogik darstellen
- ob
/search-URLs für Bots erreichbar sein müssen - ob
sort_by-Parameter indexierbare oder crawlbare Varianten erzeugen - ob Produkt-URLs mit
?variant=unnötige Duplicate-URL-Muster erzeugen - ob Tracking-Parameter wie
utm_,fbclidodergclidsauber kanonisiert werden - ob Apps zusätzliche dynamische URLs oder Parameter erzeugen
- ob Produktfeeds, Meta, Google Merchant Center und Preisvergleichsdienste eigene Abrufmuster erzeugen
Für viele Shopify-Shops ist eine sinnvolle Grundstrategie:
Wichtige Seiten erlauben:
- Startseite
- Produktseiten
- Haupt-Collections
- ausgewählte SEO-Collections
- Blogartikel
- Pages
- Sitemap
Kritische Bereiche begrenzen:
- /search
- sort_by-Parameter
- irrelevante Collection-Tags
- tiefe Pagination
- Tracking-Parameter
- nicht benötigte App-URLs
Wichtig ist: Bei Shopify sollte man nicht blind alle Collections oder Tags blockieren. Manche Collection- oder Tag-Seiten können wertvolle SEO-Landingpages sein, zum Beispiel für Marken, Produktarten, Farben oder konkrete Anwendungsfälle. Diese Seiten sollten dann bewusst gepflegt werden – mit eigenem Title, Meta Description, Beschreibungstext, interner Verlinkung und sauberer Canonical-Strategie.
Die beste Shopify-Strategie besteht daher aus drei Ebenen:
- SEO-wichtige Collections bewusst stärken
Diese Seiten bleiben crawlbar und werden aktiv für Google, Bing und KI-Suchsysteme optimiert. - Technische Filter- und Sortier-URLs begrenzen
Alles, was nur eine andere Reihenfolge oder zufällige Produktkombination erzeugt, sollte nicht unbegrenzt gecrawlt werden. - Bot-Traffic regelmäßig über Logs, Shopify-Analytics, Search Console und Server-/CDN-Daten prüfen
Gerade bei Shopify Plus, Headless-Setups oder Shops mit Cloudflare kann man Bot-Traffic deutlich besser analysieren und steuern.
Für Shopify gilt damit dieselbe Grundregel wie bei WooCommerce: Nicht die Plattform ist das Problem, sondern der unkontrollierte Crawl-Raum. Wer seine wichtigsten Produkt- und Collection-Seiten sauber freigibt, aber unnötige Such-, Filter-, Sortier- und Parameter-URLs begrenzt, schützt Performance, Crawl-Budget und Sichtbarkeit gleichzeitig.
Was ein SEO-sicherer Bot-Limiter nicht tun sollte
Ein schlechter Bot-Limiter kann mehr Schaden anrichten als Nutzen bringen.
Diese Fehler sollten vermieden werden:
- Googlebot pauschal blockieren
- Bingbot pauschal blockieren
- alle KI-Crawler ohne Strategie aussperren
- Produktseiten aus Versehen sperren
- Sitemaps blockieren
- CSS/JS/Bilder für Suchmaschinen unzugänglich machen
noindexals Ersatz für Crawl-Steuerung missverstehen- nur auf User-Agent vertrauen
- echte Nutzer durch harte Challenges stören
- Checkout und Warenkorb mit SEO-Regeln vermischen
- Regeln ohne Log-Auswertung erstellen
Besonders kritisch ist die Verwechslung von Indexsteuerung und Crawl-Steuerung.
noindex sagt: „Diese Seite nicht indexieren.“
robots.txt sagt: „Diese Seite nicht crawlen.“
Ein Bot-Limiter sagt: „Diese Anfrage wird unter diesen Bedingungen erlaubt, begrenzt oder blockiert.“
Das sind drei verschiedene Ebenen.
Warum das Thema 2026 und in Zukunft strategisch wichtiger wird
Die Zahl automatisierter Abrufe wird nicht sinken.
Im Gegenteil: Je wichtiger Webdaten für KI-Suche, Produktsuche, Preisvergleiche, Commerce-Automatisierung und Wettbewerbsanalysen werden, desto stärker steigt der Druck auf Websites.
Für Unternehmen bedeutet das:
- Sichtbarkeit bleibt abhängig von Crawling.
- Performance bleibt abhängig von technischer Kontrolle.
- Datenhoheit wird wichtiger.
- Serverkosten steigen, wenn Crawl-Räume nicht gesteuert werden.
- SEO wird technischer.
- Bot-Management wird Teil der Website-Architektur.
Wer heute einen großen Shop betreibt, sollte Bots nicht erst dann beachten, wenn der Server ausfällt.
Crawl-Management gehört in die gleiche Kategorie wie:
- Caching
- Core Web Vitals
- Datenbankoptimierung
- technische SEO
- Security
- Hosting-Architektur
- Log-Monitoring
Der ideale Ansatz: Crawl-Budget schützen, Sichtbarkeit erhalten
Ein intelligenter Bot-Limiter sollte wie ein Verkehrsleitsystem funktionieren.
Er lässt wichtige Besucher durch. Er reduziert unnötigen Verkehr. Er sperrt gefährliche Zufahrten. Und er hält kritische Infrastruktur frei.
Für Websites bedeutet das:
- Google darf wichtige Inhalte crawlen.
- Bing darf relevante Seiten erfassen.
- KI-Suchsysteme können strategisch gewünschte Inhalte sehen.
- SEO-Tools können kontrolliert arbeiten.
- Social Bots können Vorschauen erzeugen.
- Scraper werden begrenzt.
- teure Filter- und Suchseiten werden reduziert.
- echte Nutzer und Kunden haben Priorität.
Das Ergebnis ist nicht weniger Sichtbarkeit.
Das Ergebnis ist bessere technische Kontrolle über Sichtbarkeit.
Fazit: Die Zukunft gehört nicht dem offenen oder geschlossenen Web – sondern dem gesteuerten Web
Die Crawler-Flut 2026 ist kein kurzfristiges Phänomen. Sie ist die Folge eines Webs, in dem Daten immer wertvoller werden.
Suchmaschinen brauchen Daten. KI-Systeme brauchen Daten. SEO-Tools brauchen Daten. Preisvergleiche brauchen Daten. Wettbewerber wollen Daten.
Für Website-Betreiber entsteht daraus eine neue Verantwortung: Sie müssen entscheiden, welche Systeme welche Inhalte in welcher Tiefe und mit welcher Geschwindigkeit abrufen dürfen.
Ein pauschales „Alles erlauben“ ist technisch riskant.
Ein pauschales „Alles blockieren“ ist strategisch riskant.
Der richtige Weg liegt dazwischen:
intelligentes, SEO-sicheres Crawl-Management.
Moderne Websites brauchen keinen simplen Bot-Blocker. Sie brauchen einen Bot-Limiter, der versteht, welche Bots wichtig sind, welche URLs wertvoll sind und welche Zugriffe nur Serverlast erzeugen.
Denn Sichtbarkeit entsteht nicht dadurch, dass jeder alles crawlen darf.
Sichtbarkeit entsteht dadurch, dass die richtigen Systeme die richtigen Inhalte zuverlässig erreichen.
FAQ: Crawler-Flut, Bot-Limiter und Crawl-Management
Was ist ein Bot-Limiter?
Ein Bot-Limiter ist eine technische Lösung, die automatisierte Zugriffe auf eine Website kontrolliert. Im Unterschied zu einem einfachen Bot-Blocker sperrt er nicht pauschal alles, sondern unterscheidet nach Bot-Typ, URL-Muster, Frequenz, Serverlast und SEO-Relevanz.
Ist ein Bot-Limiter schlecht für SEO?
Nein, wenn er sauber umgesetzt ist. Ein guter Bot-Limiter schützt wichtige SEO-Seiten und begrenzt vor allem unnötige oder teure URL-Muster wie Filterkombinationen, interne Suche, Sortierungen und sehr tiefe Pagination.
Sollte man Googlebot begrenzen?
Googlebot sollte nicht pauschal blockiert werden. Es kann aber sinnvoll sein, Googlebot gezielt von irrelevanten Parameter- und Filter-URLs fernzuhalten. Google selbst empfiehlt bei facettierter Navigation häufig, unnötige Filter-URLs per robots.txt vom Crawling auszuschließen, wenn sie keinen eigenständigen Nutzen haben.
Reicht robots.txt als Lösung?
Nein. robots.txt ist wichtig, aber nur eine Anweisung an kooperative Crawler. Seriöse Bots respektieren sie, aggressive Scraper nicht immer. Ein intelligenter Bot-Limiter ergänzt robots.txt durch technische Regeln, Rate Limits, Mustererkennung und Bot-Verifizierung.
Sollte man KI-Crawler blockieren?
Das hängt von der Strategie ab. Wer in KI-Suchsystemen sichtbar sein möchte, sollte nicht blind alle KI-Crawler blockieren. Sinnvoller ist eine differenzierte Steuerung: redaktionelle Inhalte und wichtige Landingpages erlauben, teure Shop-Parameter und interne Suchseiten begrenzen.
Welche URLs sind bei WooCommerce besonders kritisch?
Besonders kritisch sind Filter-URLs, Sortierparameter, interne Suchseiten, tiefe Pagination, per_page-Parameter, Warenkorb-URLs, Checkout-Bereiche, AJAX-Endpunkte und kombinierte Parameter-URLs.
Warum verursachen Filterseiten so viel Last?
Filterseiten lösen häufig komplexe Produkt-, Attribut-, Taxonomie- und Meta-Abfragen aus. Wenn Bots viele Filterkombinationen abrufen, entstehen sehr viele dynamische Seitenaufrufe mit hoher Datenbanklast.
Ist Caching nicht ausreichend?
Caching hilft, löst aber nicht alles. Viele Bot-URLs sind durch Query-Parameter, dynamische Filter, Sessions oder nie zuvor aufgerufene Kombinationen nicht effizient cachebar. Ein Bot-Limiter reduziert unnötige Requests, bevor sie teuer werden.
Woran erkennt man Bot-Probleme?
Typische Hinweise sind hohe Serverlast, viele Requests auf Parameter-URLs, langsame Datenbankabfragen, 500er-Fehler, Timeouts, hohe Zugriffe auf interne Suche, ungewöhnliche User-Agents und tiefe Pagination-Aufrufe durch Bots.
Was ist das Ziel von Crawl-Management?
Das Ziel ist, wichtige Inhalte für Suchmaschinen und relevante Systeme erreichbar zu halten, während unnötige, teure oder schädliche Bot-Zugriffe reduziert werden. Crawl-Management schützt Performance, Serverkosten und Sichtbarkeit gleichzeitig.
Auch ein verwandtes Thema:
sowie:




{kind=link}
{kind=link}
{kind=link}